伦敦当地时间10月18日18:00(北京时间19日01:00),AlphaGo再次登上世界顶级科学杂志——《自然》。
一年多前,AlphaGo便是2016年1月28日当期的封面文章,Deepmind公司发表重磅论文,介绍了这个击败欧洲围棋冠军樊麾的人工智能程序。
今年5月,以3:0的比分赢下中国棋手柯洁后,AlphaGo宣布退役,但DeepMind公司并没有停下研究的脚步。伦敦当地时间10月18日,DeepMind团队公布了最强版AlphaGo ,代号AlphaGo Zero。它的独门秘籍,是“自学成才”。而且,是从一张白纸开始,零基础学习,在短短3天内,成为顶级高手。
团队称,AlphaGo Zero的水平已经超过之前所有版本的AlphaGo。在对阵曾赢下韩国棋手李世石那版AlphaGo时,AlphaGo Zero取得了100:0的压倒性战绩。DeepMind团队将关于AlphaGo Zero的相关研究以论文的形式,刊发在了10月18日的《自然》杂志上。
“AlphaGo在两年内达到的成绩令人震惊。现在,AlphaGo Zero是我们最强版本,它提升了很多。Zero提高了计算效率,并且没有使用到任何人类围棋数据,”AlphaGo之父、DeepMind联合创始人兼CEO 戴密斯?哈萨比斯(Demis Hassabis)说,“最终,我们想要利用它的算法突破,去帮助解决各种紧迫的现实世界问题,如蛋白质折叠或设计新材料。如果我们通过AlphaGo,可以在这些问题上取得进展,那么它就有潜力推动人们理解生命,并以积极的方式影响我们的生活。”
不再受人类知识限制,只用4个TPU
AlphaGo此前的版本,结合了数百万人类围棋专家的棋谱,以及强化学习的监督学习进行了自我训练。
在战胜人类围棋职业高手之前,它经过了好几个月的训练,依靠的是多台机器和48个TPU(谷歌专为加速深层神经网络运算能力而研发的芯片)。
AlphaGo Zero的能力则在这个基础上有了质的提升。最大的区别是,它不再需要人类数据。也就是说,它一开始就没有接触过人类棋谱。研发团队只是让它自由随意地在棋盘上下棋,然后进行自我博弈。值得一提的是,AlphaGo Zero还非常“低碳”,只用到了一台机器和4个TPU,极大地节省了资源。
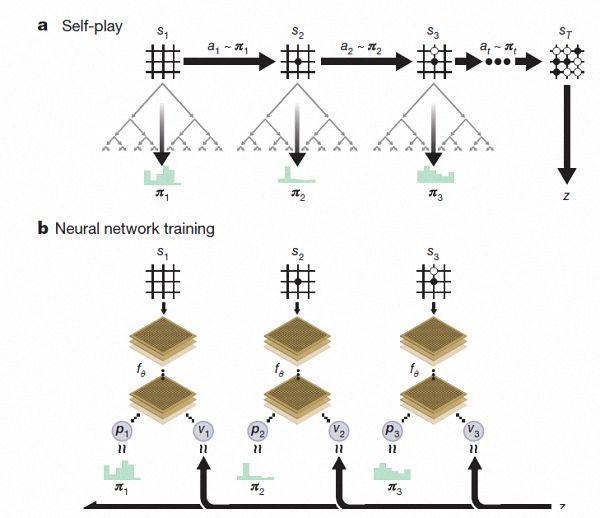
AlphaGo Zero强化学习下的自我对弈。
经过几天的训练,AlphaGo Zero完成了近5百万盘的自我博弈后,已经可以超越人类,并击败了此前所有版本的AlphaGo。DeepMind团队在官方博客上称,Zero用更新后的神经网络和搜索算法重组,随着训练地加深,系统的表现一点一点地在进步。自我博弈的成绩也越来越好,同时,神经网络也变得更准确。