第三,AlphaGo Zero并不使用快速、随机的走子方法。在此前的版本中,AlphaGo用的是快速走子方法,来预测哪个玩家会从当前的局面中赢得比赛。相反,新版本依靠地是其高质量的神经网络来评估下棋的局势。
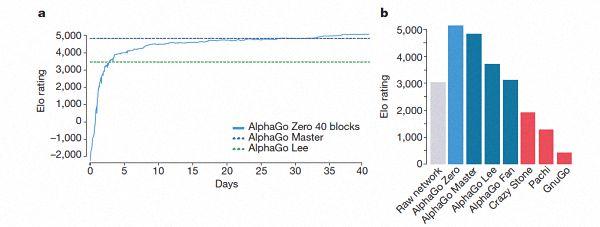
AlphaGo几个版本的排名情况。
据哈萨比斯和席尔瓦介绍,以上这些不同帮助新版AlphaGo在系统上有了提升,而算法的改变让系统变得更强更有效。
经过短短3天的自我训练,AlphaGo Zero就强势打败了此前战胜李世石的旧版AlphaGo,战绩是100:0的。经过40天的自我训练,AlphaGo Zero又打败了AlphaGo Master版本。“Master”曾击败过世界顶尖的围棋选手,甚至包括世界排名第一的柯洁。
对于希望利用人工智能推动人类社会进步为使命的DeepMind来说,围棋并不是AlphaGo的终极奥义,他们的目标始终是要利用AlphaGo打造通用的、探索宇宙的终极工具。AlphaGo Zero的提升,让DeepMind看到了利用人工智能技术改变人类命运的突破。他们目前正积极与英国医疗机构和电力能源部门合作,提高看病效率和能源效率。